
ORN #33 Das Mammut-Projekt


Mein Social-Media-Umfeld ist größtenteils von Twitter geflohen und postet jetzt mit Mastodon im Fediverse. Höchste Zeit für einen Blick auf passende Werkzeuge! Im Werkstatt-Interview erklärt Niclas Bodenmann, Praktikant im SRF-Datenteam, wie er hasserfüllte Amazon-Rezensionen untersucht hat. Im Fokus stand der mit dem Deutschen Buchpreis prämierte Roman "Blutbuch" von Kim de l'Horizon. Willkommen zu Ausgabe #33.
Debirdify: Twitter-Follower*innen zu Mastodon mitnehmen
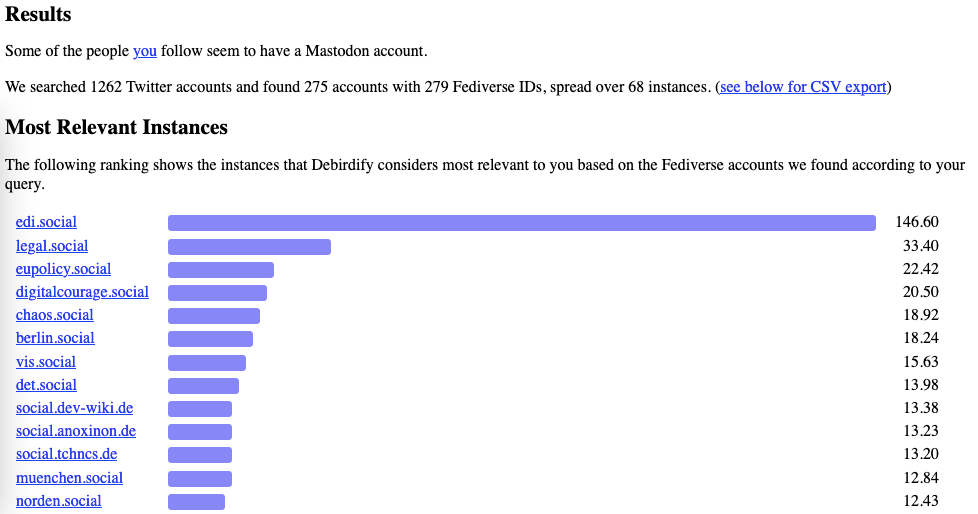
Screenshot: Debirdify
Wofür braucht man das? Wer zu Mastodon wechselt, muss nicht bei Null anfangen. Das Werkzeug Debirdify findet in wenigen Sekunden heraus, wer aus der eigenen Twitter-Gefolgschaft auch im Fediverse einen Account hat. Das Ergebnis ist eine Tabelle, die sich bei Mastodon mit wenigen Mausklicks importieren lässt. Schwupps, sind die Followings übertragen. Viele folgen dankbar zurück, weil auch sie gerade ihr neues Umfeld im Fediverse aufbauen.
Wie funktioniert das? Debirdify nutzt die Programmierschnittstelle (API) von Twitter. Dafür werden die Login-Daten eines Twitter-Accounts benötigt. Dann durchforstet die Software Twitter-Accounts nach Hinweisen auf Fediverse-Profile, beispielsweise in der Kurzbio. Wer also von anderen gefunden werden möchte, sollte das eigene Mastodon-Profil auf Twitter verlinken. Als nächstes überprüft Debirdify, ob diese Profile tatsächlich im Fediverse zu finden sind. Das Ergebnis ist eine bei Mastodon importierbare Tabelle im Dateiformat "csv", die sich per Mausklick herunterladen lässt.
Was muss man beachten? Bei Debirdify kann man sich aussuchen, ob man gefolgte Accounts, Follower*innen oder Twitter-Listen nach Fediverse-Accounts abgrasen möchte. Es ist sogar möglich, das bei anderen Accounts als dem eigenen zu tun. Hinter dem Tool steckt der Computer Scientist Manuel Eberl von der Universität Innsbruck. Ein vergleichbares Tool ist der Fedifinder von Social-Media-Analyst Luca Hammer.
Achtung: Am 9. Februar wird Twitter den kostenfreien Zugriff auf die Programmierschnittstelle beenden. Das ist nicht gut. Entsprechend können API-basierte Tools dann nicht mehr funktionieren – oder kostenpflichtig werden.
Infobox: WTF ist das Fediverse?
⚙️ Das Fediverse ist ein Zusammenschluss aus mehreren Online-Diensten. Einer davon ist das Twitter-ähnliche Mastodon, es gibt aber auch das YouTube-ähnliche PeerTube oder das Instagram-ähnliche Pixelfed. Durch den aktuellen Hype ist Mastodon bei Weitem der größte Dienst im Fediverse. Eine Übersicht dazu liefert der Fediverse Observer.
🦣 Mastodon ist ein Dienst für Micro-Blogging im Fediverse, also dem Veröffentlichen kurzer Text-Beiträge. Man kann sie mit Hashtags, Links und Bildern ergänzen. Viele suchen darin ihr neues soziales Netzwerk, nachdem Elon Musk Twitter gegen die Wand fährt. Als dezentrales Netzwerk besteht Mastodon aus mehreren Instanzen.
🏡 Eine Instanz ist wie ein Dorf im Fediverse. Im Gegensatz zu Twitter oder Facebook erstellen Nutzer*innen ihre Accounts nicht bei einem zentralen Anbieter, der dann die Kontrolle über alle Server und Inhalte hat. Stattdessen kann jede Person auf eigenen Servern eine eigene Instanz betreiben. Nutzer*innen können dann dort ihre Accounts erstellen und Inhalte posten. Die Betreiber*innen der Instanz können ihre eigenen Regeln zur Content Moderation aufstellen. Nutzer*innen können sich problemlos über Instanzen und Dienste hinweg folgen.
📯 Toots oder Tröts sind das Mastodon-Wort für Tweets, das Verb dazu ist tooten oder tröten. Boosten ist das Mastodon-Wort für Retweeten.
📱 Ein Client ist eine Anwendung, um das Fediverse zu nutzen, ich habe mich für Tusky (Android) entschieden. Tutorials für die ersten Schritte bei Mastodon haben meine Kolleg*innen auf netzpolitik.org veröffentlicht.
Social Search: Fediverse-Accounts finden
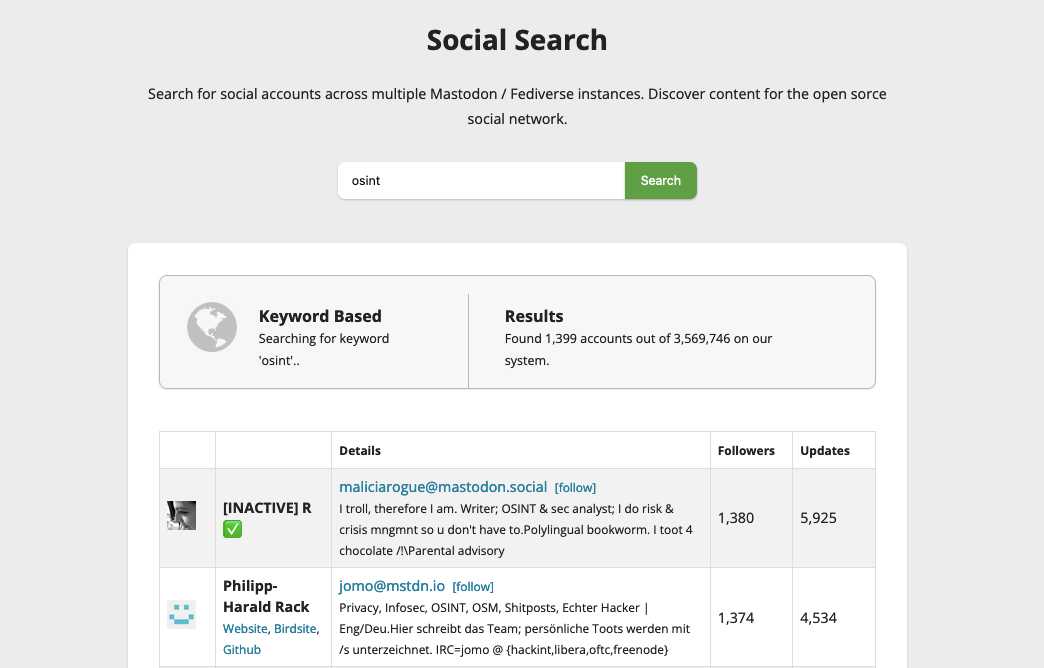
Screenshot: Social Search
Was muss man beachten? Das Fediverse lässt sich nicht so leicht durchforsten wie Twitter oder Facebook. Eine schlichte Volltext-Suche nach Stichworten sucht man hier vergeblich. Und das ist Absicht. Die selbst auferlegte Beschränkung soll verhindern, dass Gemeinschaften und ihre Gespräche so einfach von Außen gestört werden. Zum Beispiel, weil manche Trolle und Hetzer*innen nichts lieber tun, als Online-Debatten zu vergiften. Dafür suchen sie gezielt nach Stichworten wie "gendern" oder "queer". Wer einfach gefunden werden möchte, muss ausdrücklich Hashtags nutzen.
Wofür braucht man das? Das Werkzeug Social Search macht das Auffinden einzelner Accounts im Fediverse etwas leichter. Es respektiert dennoch den Verzicht auf Volltext-Suche, denn Social Search bezieht sich allein auf Account-Namen und Kurzbios. Mehr als 3,5 Millionen Accounts sollen damit durchsuchbar sein.
Wie funktioniert das? Das Werkzeug stammt vom Entwickler Daniel Cid. Da es kein zentrales Verzeichnis aller Fediverse-Accounts gibt, sammelt Social Search die Daten selbstständig, entsprechend sind die Angaben nicht immer aktuell.
🍱 Alle Beiträge aus diesem Newsletter landen in einem leicht durchsuchbaren Online-Archiv.
🤝 Von derzeit rund 1.700 Abonnent:innen supporten 17 diesen Newsletter auf Steady. Vielen lieben Dank dafür!
❤️ Zeige jetzt, dass Dir guter Journalismus etwas wert ist, und unterstütze den Online-Recherche Newsletter hier auf Steady.
Interview: Review Bombing auf Amazon durchleuchten

Foto: Niclas Bodenmann
Eine Welle von Queerfeindlichkeit brach über Kim de l'Horizon herein, nachdem der Roman "Blutbuch" mit dem Deutschen Buchpreis prämiert wurde. Die Spuren des Hasses finden sich auch auf Amazon. Im Rahmen seines Praktikums im Datenteam des SRF (Schweizer Radio und Fernsehen) hat Niclas Bodenmann das Phänomen untersucht. Im Interview erklärt der Student der Computerlinguistik, wie sich die Toxizität von Texten messen lässt – und welche Teile der Daten-Recherche im Papierkorb gelandet sind.
Niclas, du hast Hunderte Amazon-Bewertungen für den Roman "Blutbuch" untersucht. Warum?
Kim de l'Horizon bekam nach der Verleihung des Deutschen Buchpreises viel Hass ab. Für den Auftritt bei der Buchmesse wurde Personenschutz benötigt. Wir haben uns gefragt, wo können wir dazu Daten finden? Wir kamen auf die Idee, uns dafür Bewertungen auf Online-Portalen anzuschauen. Also haben wir mehrere Buchverkaufsseiten gesichtet und schnell gemerkt, dass auf Amazon am meisten zu finden ist. Die Analyse hat ein klares Bild gezeichnet: Kim de l'Horizon wurde in den Bewertungen deutlich härter kritisiert als die vorangegangen Buchpreisträger*innen. Die Bewertungen und Kommentare sind viel harscher und viel toxischer.
Woran macht ihr das fest?
Zuerst hatten wir uns nur die Amazon-Bewertungen von "Blutbuch" angeschaut und hatten den Eindruck: Das ist schon brutal, was dort abgeht. Aber wir brauchten einen Referenzrahmen. Also haben wir die Bewertungen mit denen der prämierten Bücher aus den Vorjahren verglichen. Daraus konnten wir ablesen, Blutbuch hat viel mehr 1-Sterne-Bewertungen als die anderen Bücher, und die niedrigen Bewertungen wurden deutlich häufiger mit einem Daumen nach oben als "hilfreich" bewertet. Wir haben außerdem einen Service genutzt, mit dem sich messen lässt, inwiefern Texte inhaltlich hasserfüllt sind. So konnten wir ablesen, dass besonders die hasserfüllten Amazon-Bewertungen extrem viel Zuspruch bekommen haben.
Mit welchen Werkzeugen habt ihr die Daten erfasst?
Wir haben einen Crawler geschrieben, der die Amazon-Bewertungen erfasst sowie dazu gehörige Informationen wie die Anzahl der Sterne. Ein Crawler ist eine Software, die das Internet absucht. Ich hatte unseren Crawler zuerst im 12-Stunden-Takt laufen lassen und Daten zu mehreren Zeitpunkten erfasst. Diesen Vergleich der Daten zu mehreren Zeitpunkten haben wir am Ende aber nicht weiter vertieft. Man konnte darin sehen, dass neue Kommentare hinzukommen und ältere Kommentare gelöscht wurden. Das hätte die Analyse aber nur komplizierter gemacht und wenig am Ergebnis geändert.
Wie schwer ist das, einen Crawler für Amazon zu schreiben?
Da wir für fast alle Projekte Crawler schreiben müssen, ist das ziemlich zu einer Routine geworden. Man braucht definitiv Programmierkenntnisse. Amazon ist eine der härteren Knacknüsse, denn die Seite blockiert irgendwann deine IP-Adresse, um automatische Abfragen zu verhindern. Also haben wir gewisse Tricksereien wie rotierende IP-Adressen genutzt, um zu verschleiern, dass wir maschinell Daten abgreifen.
Mit welchem Werkzeug habt ihr ausgewertet, wie hasserfüllt Amazon-Bewertungen waren?
Dafür haben wir PerspectiveAPI genutzt. Das ist ein gutes Stück einfacher, als einen Crawler zu schreiben. Man muss dafür nur wissen, wie man eine API-Anfrage schickt. Aber es ist wichtig, dass man kritisch hinterfragt, was PerspectiveAPI überhaupt berechnet. Es ist ein Machine-Learning-Modell, das für einen untersuchten Text einen Wert herausgibt, zum Beispiel: 0,76. Dieser Wert sagt allerdings nicht direkt, wie toxisch oder hasserfüllt eine Äußerung ist. Er soll angeben, welcher Prozentsatz von Leuten diese Äußerung wahrscheinlich als hasserfüllt einstufen würde.
Wir haben diskutiert, ob wir mithilfe von PerspectiveAPI überhaupt sinnvolle Daten für unsere Recherche gewinnen können. Dafür haben wir uns Stichproben von Kommentaren angeschaut und überprüft, ob die Werte von PerspectiveAPI mit unseren Vorstellungen von Hass und Beleidigungen übereinstimmen. So sind wir zu dem Schluss gekommen, dass wir den Service durchaus als Indikator dafür nutzen können, wie hasserfüllt die Amazon-Bewertungen sind.
"Sprache als datenjournalistisch auswertbare Quelle betrachten"
Heißt das, PerspetiveAPI zählt einfach die Dichte an mutmaßlichen Schimpfwörtern in einem Text?
Es ist bestimmt ein gutes Stück komplizierter. Ich habe dazu einen praktischen Hintergrund aus meiner universitären Ausbildung in der Computerlinguistik. Dort entwickeln wir genau solche Modelle. Das sind komplexe neuronale Modelle, die mitunter einen Text auf einzelne Silben herunterbrechen und miteinander verrechnen. So lässt sich nicht mehr sagen: Dieses eine Wort hat zu Toxizität geführt. Es gibt viel mehr Faktoren. Diese Komplexität ist jedoch wünschenswert, denn je nach Kontext ist ein Wort gar nicht als Schimpfwort zu verstehen, zum Beispiel wenn es in einer Verneinung auftaucht.
Wie cool, dass du genau das studierst!
Ja, das ist eine der Sachen, die ich aus dem Studium ins Praktikum mitgebracht habe: dass man auch Sprache als datenjournalistisch auswertbare Quelle behandeln kann.
Womit hast du die Grafiken gebaut?
Zuerst habe ich die Daten mit matplotlib visualisiert, das ist eine Bibliothek für die Programmiersprache Python. Aber für die Veröffentlichung auf der Website mussten wir auf Datawrapper zurückgreifen. Datawrapper ist ein Online-Service, um einfache Visualisierungen zu erstellen und zu hosten. Das heißt, der Service unterstützt weniger Diagrammtypen als matplotlib. Während der Recherche sind viele Visualisierungen entstanden, die wir am Ende nicht im Artikel zeigen konnten.
Ist das schade, wenn Visualisierungen im Papierkorb landen?
Manche Dinge kann man auch gut in Worten erzählen und muss sie nicht visualisieren. Von der Recherche im Team bis zum fertigen Artikel findet eine extreme Reduktion statt. Manche Visualisierungen mussten wir wegen mangelnder Verständlichkeit opfern. Zum Beispiel habe ich hier gerade eine Grafik vor mir, in der wir uns angeschaut haben, wie sich die verifizierten und unverifizierten Amazon-Bewertungen für jedes der zehn Bücher auf die Sterne-Bewertungen verteilen.
Nochmal langsamer bitte: Was genau sieht man in der Grafik?
Also, sie hat sehr viele Dimensionen. Da sind die 10 Bücher, und für jedes dieser Bücher gibt es ein Balkendiagramm mit der Anzahl der Bewertungen, aufgeteilt in eins, zwei, drei, vier und fünf Sterne. Diese Balken sind in sich noch einmal geschichtet und zeigen, ob die Bewertungen von verifizierten oder nicht-verifizierten Käufen stammen, und ob zu der Bewertung noch ein schriftlicher Kommentar hinterlassen wurde oder nicht.
Jetzt verstehe ich, warum das vielleicht zu kompliziert für deinen Artikel war.
Ja! Es war ein super praktisches Arbeitswerkzeug während der Recherche, weil wir darin mega viele Informationen auf einen Blick hatten. Aber man muss sich schon eine Weile mit dem Datenset befassen, damit eine solche Visualisierung Sinn macht.
Darf ich die Grafik zumindest im Newsletter veröffentlichen? Ich glaube, wer das Interview bis zu dieser Stelle gelesen hat, ist jetzt neugierig.

Grafik: Niclas Bodenmann
Was verrät die Recherche über das Phänomen Review Bombing, also dass Nutzer*innen gezielt und massenhaft schlechte Bewertungen hinterlassen, um den Ruf einer Produkts zu schaden?
Es zeigt, dass Review Bombing nicht nur im angelsächsischen Raum betrieben wird, sondern auch bei uns. Ich sehe persönlich die Betreiber*innen von Online-Plattformen in Pflicht, mehr dagegen zu unternehmen. Amazon hat zwar ausführliche und strenge Richtlinien, aber es scheitert offenbar an der Anwendung. Die hasserfüllten Kommentare haben das Gesamtbild dominiert. Welchen Einfluss das in diesem Fall auf den Erfolg des Buches hat, konnten wir leider nicht messen. Wir haben diskutiert, ob wir dazu Daten finden können, etwa Verkaufszahlen oder Platzierungen in Rankings, aber wir haben keine Antwort gefunden.
Was hast du bei der Recherche gelernt?
Ich hatte zu Beginn das Bedürfnis, über den wirtschaftlichem Schaden durch den Missbrauch von Online-Bewertungen zu berichten. Aber ich wurde im Rahmen des Praktikums immer wieder daran erinnert, dass die Daten das nicht belegen. Es ist wichtig, dass man nicht bloß Daten findet, die zu der Erzählung passen, die man vielleicht vor Augen hat, sondern dass man wirklich das erzählt, was aus den Daten hervorgeht.
Teile deine Recherche-Skills mit anderen 🤝
und leite den Newsletter jetzt an eine Kolleg*in weiter
Alle Werkzeuge schnell und einfach wiederfinden: Ein mit Schlagworten durchsuchbares Archiv der bisherigen Beiträge gibt es auf ornarchiv.wordpress.com. Und hier ist eine übersichtliche Linkliste mit noch mehr Tools.
Lieben Dank fürs Lesen und viel Erfolg bei der Recherche!
Sebastian